
Scanned documents and images are everywhere. Extracting structured data from them has always been an essential yet complex, multi-step task.
This is starting to change. Developed by major AI labs, the latest vision language models (VLMs) can now read text and also understand layout, labels, and structure. With these models, the traditional OCR pipeline can be squashed into a single step. You can now upload a form, provide a schema, and receive structured JSON directly. No rules, no regex, no cleanup.
Even better, by fine-tuning for a specific use-case, smaller models can perform as well as frontier-models. For example, we will discuss how we fine-tuned an 8B-parameter model for a customer’s specific task and achieved the same accuracy as models 30x the size. This fine-tuned model runs faster, costs less, and doesn't have any data privacy issues.
Traditional OCR pipelines typically follow a two-stage process:
While this works well for clean, printed text, it struggles in many real-world scenarios due to two main limitations:
VLMs can simplify OCR by turning this multi-stage pipeline into a single, end-to-end process. Instead of first detecting text, then parsing it, a VLM can read the entire document and directly output structured data. While doing so, it sees not only the characters, but also the layout, labels, and relationships between fields. This makes the whole system simpler and more reliable.
It works because these VLMs have already been trained on massive collections of text, images, and real-world documents across countless formats and languages. As a result, they come with a strong understanding of most languages and document types right out of the box.
Building a capable OCR system is now as simple as writing a natural language prompt. No specialized rules or post-processing required. Just describe the task, provide the image, and get the output.
Even better, the quality of these VLMs continues to improve rapidly. Advances in training infrastructure, algorithms, and data generation make these models more capable with each iteration.
At Ubicloud, we host inference endpoints for leading open-source vision language models. To illustrate this end-to-end OCR workflow, we use a scanned handwritten form, a JSON schema, and a single model call.
Traditionally, this would take multiple steps: OCR, parsing, and validation. With a VLM, it’s one step.
api_key = os.getenv("UBICLOUD_API_KEY")
client = OpenAI(api_key=api_key, base_url="https://us-east-a2.ai.ubicloud.com/v1")
form_schema = {
"name": "FormData",
"schema": {
"type": "object",
"properties": {
"date": {"type": "string", "pattern": r"^\d{2}-\d{2}-\d{2}$", "description": "Date in mm-dd-yy format"},
"state": {"type": "string"},
"zip": {"type": "string", "pattern": r"^[0-9\\-]+$"}
},
"required": ["date", "state", "zip"],
"additionalProperties": False
},
"strict": True
}
messages = [
{"role": "system", "content": "You are an OCR assistant. Extract fields from this scanned document as structured JSON."},
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,<encoded-image>"}}
]}
]
completion = client.chat.completions.create(
model="Qwen/Qwen3-VL-235B-A22B-Instruct-FP8",
messages=messages,
response_format={"type": "json_schema", "json_schema": form_schema},
temperature=0.0
)
Because the output is schema-constrained, the model returns valid JSON that fits the format. There’s no regex cleanup or post-processing. The result is structured and ready to use.
You can obtain your Ubicloud API key by logging into the Ubicloud Console, navigating to “AI Inference” → “API Keys” under your project settings, and clicking “Create API Key” to generate your key.
Finally, note that the temperature parameter is set to 0.0 for better determinism and reliability. Higher temperatures introduce randomness to encourage creativity, which is useful for open-ended tasks but can reduce accuracy in structured data extraction. Setting it to zero ensures consistent and precise outputs. This is essential for accuracy-critical workflows.
Try it yourself in our Colab notebook. Upload your own image and JSON schema to see the end-to-end OCR workflow in action.
We evaluated several leading vision language models on real-world forms containing both printed and handwritten text. For each model, we prompted it with an instruction to extract the fields directly into a JSON schema. Then, we calculated the field-level accuracy.
The evaluation dataset is private since it contains PII information. However, we believe the relative performance should provide a meaningful indication of how these models perform on broader end-to-end OCR tasks.
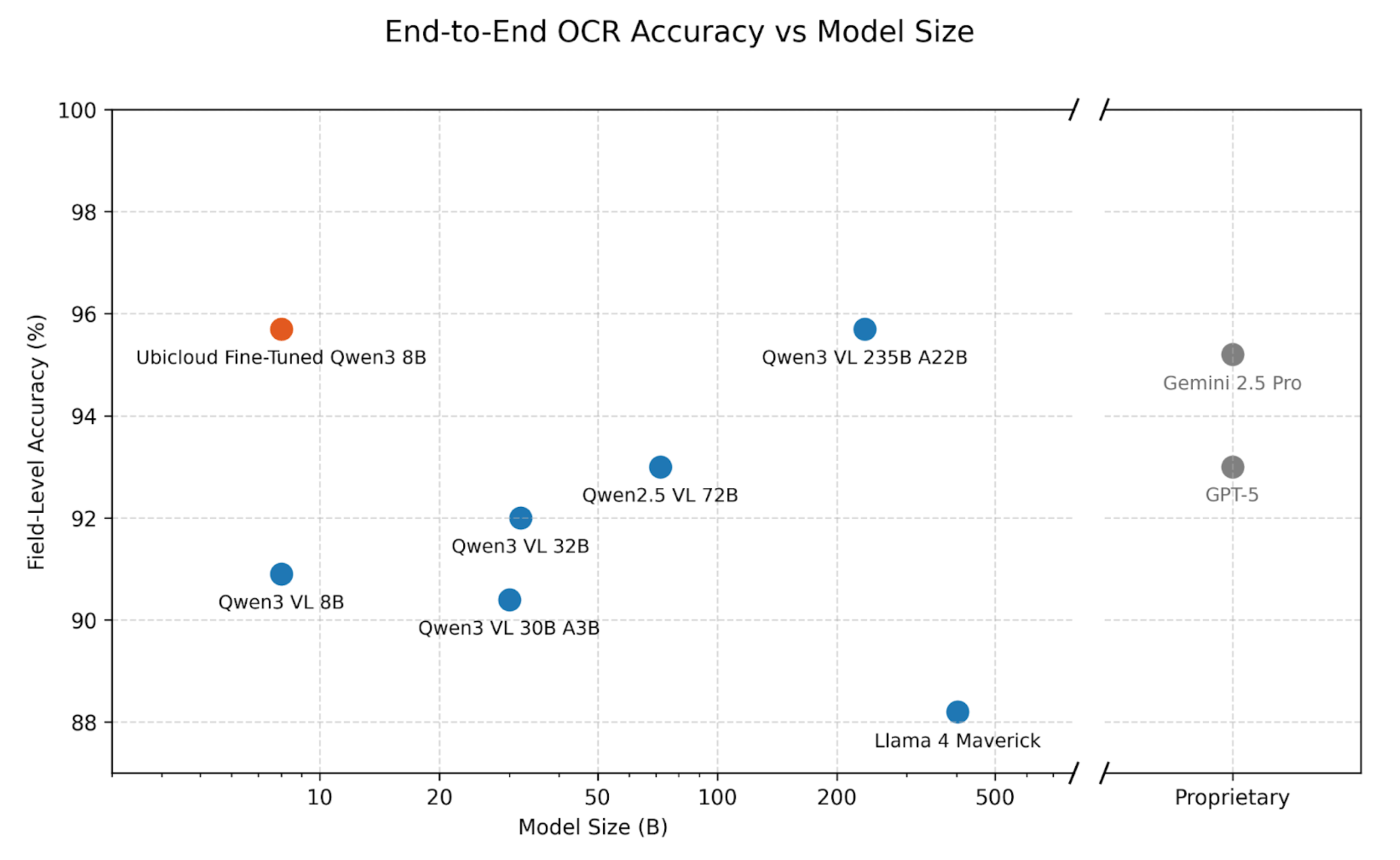
The results show that large vision language models, such as Qwen3 VL 235B A22B and Gemini 2.5 Pro, achieve top-tier accuracy out of the box. Both exceeded 95%. For the Qwen model series, accuracy increases roughly linearly with the logarithm of model size, consistent with the LLM scaling law.
The Ubicloud fine-tuned 8B model achieves accuracy comparable to the largest Qwen3 model and Gemini 2.5 Pro. This model was fine-tuned for the specific form types in the evaluation dataset. The next section provides more details on the fine-tuning process.
For our customer’s specific task, we fine-tuned an 8B Qwen3 model, and it achieved the same accuracy as the 30x larger Qwen3 model and Gemini 2.5 Pro.
During fine-tuning, we used 20 manually labeled forms from our customer and 2,000 synthetically generated forms we created as the training dataset. These forms are not part of the evaluation dataset, and their handwriting styles differ from those in the evaluation dataset. However, they all do share the same layout.
To prevent overfitting on limited handwriting styles, we used several techniques:
In reinforcement fine-tuning, the model is rewarded for minimizing the Levenshtein edit distance instead of maximizing field-level accuracy. This gives partial credit for partially correct fields. We found it especially helpful for providing consistent and efficient learning signals, particularly on more challenging samples.
The fine-tuning took about one day on a single B200 and cost about $100. Most of the time was spent on image tokenization.
The result was a compact 8B-parameter model that matched the accuracy of models 30x larger and the best proprietary model. It runs faster, costs less, and avoids data privacy issues. Its overall error rate dropped by half compared to the original Qwen3 8B model. Its error rate for printed text dropped from 4.6% to 0.0%. The table below summarizes the results.
| Model | Field-Level Error % (Overall) | Field-Level Error % (Printed Only) | Field-Level Error % (Handwritten Only) |
|---|---|---|---|
Qwen3 VL 8B | 9.1% | 4.6% | 10.5% |
Ubicloud Fine-Tuned Qwen3 8B | 4.3% | 0.0% | 5.6% |
Qwen3 VL 235B A22B | 4.3% | 0.0% | 5.6% |
Gemini 2.5 Pro | 4.8% | 0.0% | 6.2% |
Vision language models (VLMs) are advancing rapidly and bringing OCR into a new end-to-end era. They understand both the content and structure of documents, allowing them to extract information directly. This makes the entire OCR process simpler, more reliable, and far easier to maintain.
For many OCR tasks, an off-the-shelf VLM can already deliver strong results without task-specific fine-tuning. If you haven’t tried it yet, we encourage you to explore our Colab notebook and experiment with your own images and JSON schema. You might be surprised by how well it works out of the box.
For projects that demand even higher accuracy or lower inference costs, we are happy to help fine-tune these models for your specific workflows.
With the rapid progress of vision language models, we believe this end-to-end OCR approach can significantly improve operational accuracy and create substantial value for many businesses.








