Managed PostgreSQL
Read Replica Upgrades Now Automatic
Read replicas are now automatically upgraded alongside their parent database during PostgreSQL version upgrades. Instead of requiring manual intervention, the system creates a new server using the latest timeline and version, then performs a seamless failover once ready. This eliminates the operational overhead of coordinating replica upgrades separately.Enhanced Restore Progress Visibility
PostgreSQL restore operations now display more detailed status information in the UI and API. You can now see specific states including “restoring backup”, “replaying WAL”, and “finalizing restore” during point-in-time recovery (PITR) and replica creation, giving you better insight into long-running restore operations.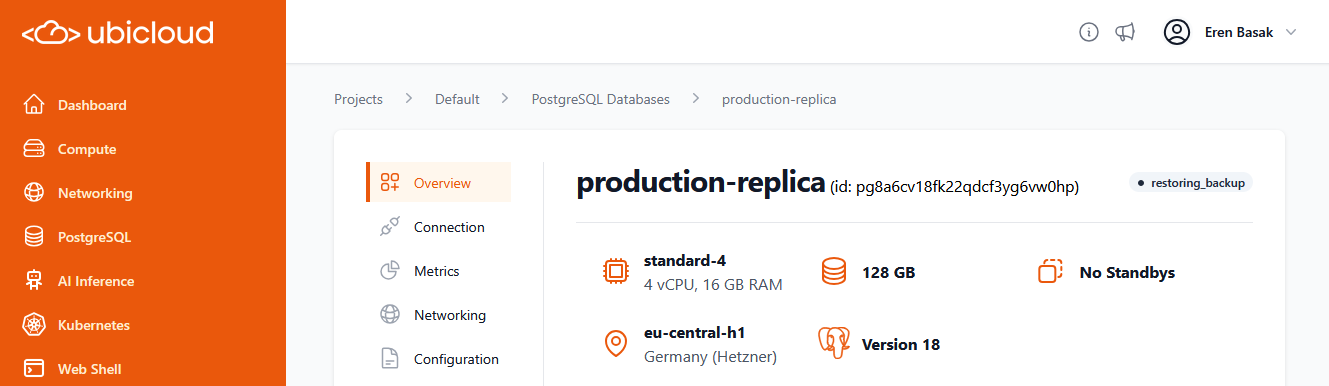
Private DNS Support for PostgreSQL
PostgreSQL databases now support private DNS entries, enabling connections via DNS names using private IP addresses. This is especially useful when connecting through private subnets, as the DNS name (private-*) remains stable even when private IPs change due to resize, upgrade, or failover operations. This is particularly useful for Kubernetes services and internal application architectures where private networking is preferred
IPv6 DNS Records for PostgreSQL
Non-AWS PostgreSQL databases now register DNS AAAA records for both public and private IPv6 addresses, enabling native IPv6 connectivity to your databases.Tags Support for Read Replicas
The API endpoint for creating PostgreSQL read replicas now accepts tags, aligning with the create database endpoint. You can now organize and categorize your read replicas using custom tags from the moment of creation.AI & GPUs
GPU Virtual Machine Access
The “Create GPU Virtual Machine” button is now visible to all users. Projects without GPU access enabled will see a helpful message explaining how to request access to NVIDIA B200 and RTX PRO 6000 GPUs by contacting support.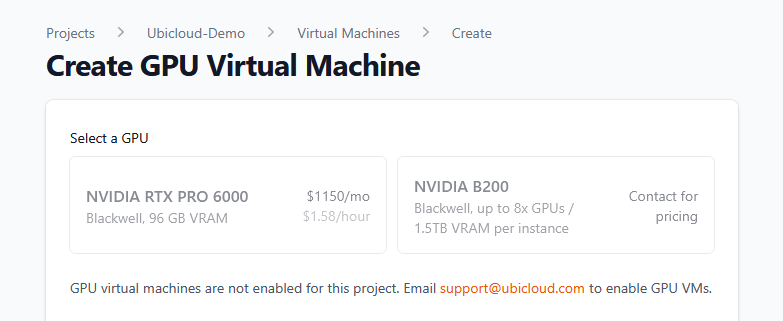
Networking
Firewall Description Updates
You can now update firewall descriptions after creation through the UI, API, and CLI. Previously, firewall descriptions could only be set during creation and couldn’t be modified afterward.Ubicloud Kubernetes
Increased Pod Capacity Per Node
Kubernetes clusters now provision larger subnets (/16 instead of /18), increasing the available IP addresses per node from 64 to 254. This allows each node to run up to 127 pods, exceeding the kubelet default of 110 and removing a previous limitation of 31 pods per node.CLI
Output Format Improvements
CLI output now uses dashes instead of underscores in field names for consistency with CLI input conventions (e.g.,storage-size instead of storage_size). This provides a more uniform experience across CLI commands.